













The global pandemic of 2020 was challenging for frontline workers, the public, and businesses. Besides a dwindling economy, governments and organizations suffered various setbacks, including exponential data thefts. Security incidents became more costly and harder to contain for the latter due to a drastic operational shift. As per experts, the cost of a data breach reached a record high, shelling $4.24 million per incident on average from affected ventures.
As more businesses migrate to the digital world, data security becomes a reason for severe migraine for owners. Keeping the incidents and the present situation in mind, the European Union introduced the General Data Protection Regulation (GDPR) for improved data privacy controls for EU citizens. GDPR requires a thorough evaluation of every software application before its implementation to prevent possible data breaches and loss of customers, employees, and corporate data. Automatically, business process management solutions, like process mining, RPA, automated process discovery, and others, fall under the tight scrutiny of GDPR data privacy guidelines.
Process Mining in Business Process Management – A Brief Overview
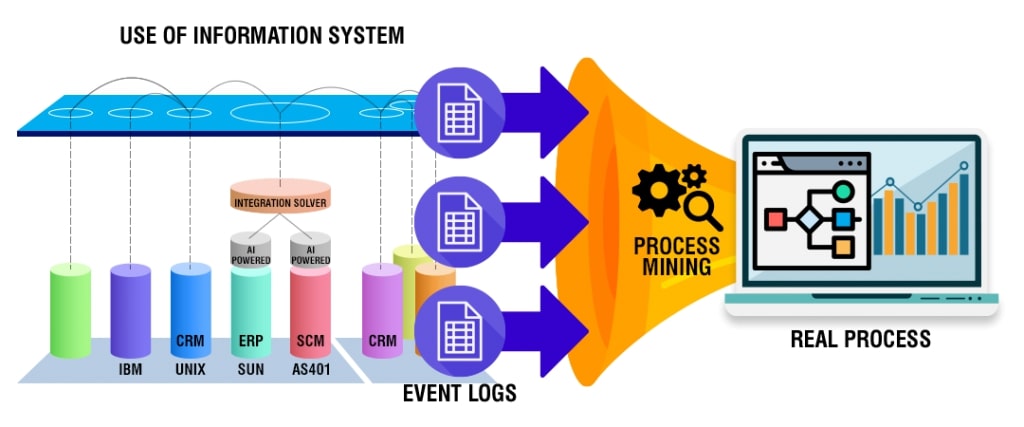
Process mining is an intelligent technology solution enabling owners to build a reliable visual map of business processes elaborating how every task within a process is executed. It captures employee-software system interactions and converts data into event logs. This provides an overview of end-to-end processes.
Process mining tools provide task and process insights to evaluate task executions for scaling improvement opportunities. These insights also support informed decision-making pertaining to process efficiencies and complexities.
Process mining bridges the gap between traditional model-based processes and data-centric processes for further analysis. There are three basic types of process mining; namely, process discovery to discover a process model capturing the behavior in an event log (collection of events), conformance checking for identifying commonalities and discrepancies between a process model and an event log, and process re-engineering to improve a process model using event logs. In a human-centric process, each event comprises a case identifier, an activity name, a timestamp, and optional attributes such as resources or costs. Usually, a case identifier refers to individuals and includes much personal data. And herein lies the significance of improving data security.
The Importance of Data Security in Process Mining
Automated process mining relies heavily on enterprise data and captures confidential information about the company or the clients. Data collected during the mining of processes are categorized under the following datasets:
Key identifiers: These datasets contain unique information identifying individuals, such as their full names and social security numbers.
Quasi-identifiers: These datasets are considered indirect identification of individuals—for example, gender, age, and postal code.
Sensitive attributes: Information related to salary, payment, financial statements, and others are private and sensitive for individuals or companies.
Insensitive attributes: These datasets contain general or non-risky information not covered by the other features.
Given the confidential and sensitive nature of the above-mentioned data, attention to cybersecurity in process mining has gained momentum recently. Also, third parties can offer the latter; therefore, choosing providers with secure products and processes is equally crucial. Any breach in data security can prove costly for the company owners and tarnish customer/client/partner relationships.
But the shared responsibility of protecting critical information should rest upon employees. After all, it is said that the usual source of security incidents are current employees and, in certain instances, ex-workers.
Respective teams, while handling information, should protect sensitive data at every step of task execution. In order to achieve the same, decisions regarding data transparency and usage should be made aforehand. Most specifically, such decisions involve the type of data used, data extraction methods, data accessibility, data protection, and compliance requirements.
On the other hand, process mining can be leveraged to detect silent internal attacks on data. It can quickly identify abnormal behavior in the company’s internal network and indicate apparent security breaches.
Therefore, data is integral to process mining, and the security of which should be the core objective of software applications and associated teams.
Key Privacy Metrics in Process Mining
In order to evaluate the privacy of specific data, owners should decide on particular metrics for measurement. These privacy metrics tally the security level of each data in terms of disclosure and are broadly categorized under the following sub-heads:
Bounded knowledge: Data is restricted with specific rules to avoid disclosing confidential information.
Need to know: The unnecessary data is eliminated from the system to prevent any breach. This metric controls data access.
Protected from disclosure: Data confidentiality is observed during data mining using the classification method.
Data quality metrics: These metrics measure the loss of information/benefit, while the complexity criteria validate the efficiency and scalability of different techniques within this scope.
Process Mining and Data Capture – Key Points to Consider
Since process mining extracts granular data at the process level, care is taken to ensure that any new process doesn’t come into conflict with personal data policies. Owners should also ascertain that software solutions for mining processes comply with the specific data security requirements. Therefore, people involved with the entire system must consider a few data capture points.
Access to raw data: The process mining team requires access to corporate data to understand what’s most important for analysis. Here, the company can choose and grant access to specific datasets for further research.
Choose the right strategy: Besides mining processes for raw insights, the team also translates the raw data into broad terms and updates it into dashboards. Later on, the respective team can decide what features to focus on.
Filter: Occasionally, the company tracks information that doesn’t require further analysis for specific processes. In this case, the data can simply be omitted from the system. Datasets that are sensitive or do not directly impact the business analysis outcome are deleted to maintain the focus only on valid and relevant data.
Pseudonymization: Encrypting the information to protect the confidentiality of sensitive information prevents users from correlating them to real data specific, like specific names, addresses, or other PII data. For instance, if the company wishes to maintain secrecy about employees directly involved with process-related tasks can follow this approach. Here, the case identifier’s name is replaced with numbers.
Anonymization: This is similar to pseudonymization, where the names are replaced with unique pseudonyms instead of numbers. Hence, unauthorized users cannot identify individuals’ names or confidential information about them from the available data.
Conclusion
Besides handling data in bulk daily, enterprises using online systems leave behind their digital footprints. These footprints are valuable data captured by process mining to examine how employees execute each process and sub-tasks. Needless to say, mining for such insights is done with the company’s best interests in mind, namely, to optimize operations and resources and derive maximum value.
However, such datasets carry sensitive information of various interested parties, any breach of which can prove highly hazardous for all. Therefore, data is the primary source for process miners to carry out their objectives, but the company must ensure the data is handled with care. Hence, data security is a significant factor in process mining.
Have A Look :-
- How to Get Copy of a Divorce Decree
- 7 Secrets To Make Your Baby Fall Asleep Faster
- All That You Need To Keep In Mind Before Selling On Facebook










